
In Part I, I introduced you to the concept of IAC(Infrastructure as Code) using Terraform, and we explored the awesomeness of Terraform. While the code we used in Part I for provisioning a simple server worked very well, the system we eventually provisioned was hardly a scalable system and not one I would recommend for production use. The reasoning is simple, running a single server for your entire application is almost as bad as lighting a match in a gas station, bad things can and will happen. To save the burns let’s look at high availability setup.
In this second part of our IAC series, we’re going to build on what we started in Part I, to create a highly available system. In Code X of Part I, we had created one server with the following code:
resource "digitalocean_droplet" "web" {
image = "ubuntu-16-04-x64"
name = "web-1"
region = "lon1"
size = "1gb"
ssh_keys = ["${digitalocean_ssh_key.default.id}"]
}Code I
You can find the code for this part on GitHub
Now let’s expand on this code and create two web servers. To do this, we will add a meta-parameter called count. The count parameter can be added to any resource and it simply creates more of the declared resource, based on its value.
resource "digitalocean_droplet" "web" {I
count = 2
image = "ubuntu-16-04-x64"
name = "web-${count.index}"
region = "lon1"
size = "1gb"
ssh_keys = ["${digitalocean_ssh_key.default.id}"]
}Code II
Notice the introduction of count = 2 in the code above? Now that’s how we create 2 web servers. If we wanted to create 10 web servers, all that we need do is to change the value of count to 10, if we need 20 servers, we change the value of count to 20, you get the idea.
We also need to create unique names for the servers; name = "web-${count.index}", this will create servers named web-0 and web-1. ${count.index} is how we loop over Terraform count meta-parameter. In traditional programming languages, we would have used a for loop like this:
for($i = 0; i <= 2; $i++) {
//
}The next thing that we need do to build our highly available system is to create a load balancer and distribute traffic to all of our servers.
Adding a load balancer is simple, all we have to do is add the digitalocean_loadbalancer resource and add a few parameters. We set the name, choose a region, apply the traffic forwarding rules, add a health check and finally, reference our our Digital Ocean droplets. That simple.
resource "digitalocean_droplet" "web" {
count = 2
image = "ubuntu-16-04-x64"
name = "web-${count.index}"
region = "lon1"
size = "1gb"
ssh_keys = ["${digitalocean_ssh_key.default.id}"]
}
resource "digitalocean_loadbalancer" "public_lb" {
name = "public-lb"
region = "lon1"
forwarding_rule {
entry_port = 80
entry_protocol = "http"
target_port = 80
target_protocol = "http"
}
algorithm = "round_robin"
droplet_ids = ["${digitalocean_droplet.web.*.id}"]
}Code III
From the resource above, the name and region are pretty self-explanatory, both are also required as is the forwarding rule. The forwarding rule tells us how to send traffic. The protocol for our load balancer is going to be HTTP which has a default port of 80. The entry_protocol and entry_port configures how traffic is sent to the load balancer and the target_port and target_protocol configures how traffic gets to the attached droplets.
The next important bit here is the connection algorithm between the load balancer and the droplets. In our case, we are chosing round robin. Although Terraform only supports two sets of algorithms for Digital Ocean’s load balancer resource — Round Robin(round_robin) and Least Connections(least_connections) — other load balancing algorithm exist like Weighted Round Robin, Least Traffic, Source IP, etc.
A round robin is an arrangement of choosing all elements in a group equally in some rational order, usually from the top to the bottom of a list and then starting again at the top of the list and so on. A simple way to think of round robin is that it is about “taking turns.” Used as an adjective, round robin becomes “round-robin.” - WhatIs.
In the last section of our load balancer resource block, we attach our droplets to the load balancer using droplet_ids. We use string interpolation to reference the droplet ids, this, is how Terraform builds its dependency graph. There is a convention to using interpolation in Terraform, it follows the pattern of ${RESOURCE_TYPE.RESOURCE_NAME.ATTRIBUTE_NAME}. In our case, we are referencing the digitalocean_droplets resource with the name of web, and we are getting all its id attributes.
The setup above is all that is needed, to put together a simple layer 4 load balancer. The only missing bit here is a database server.
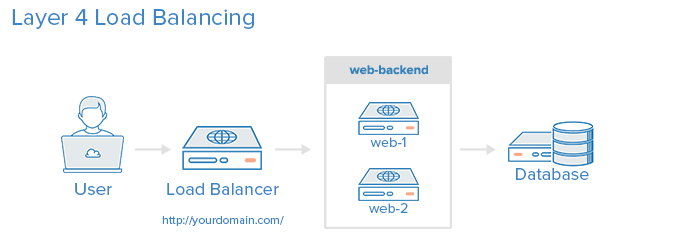 Image credit: Digital Ocean
Image credit: Digital Ocean
Adding a database is simple, at the time of this writing, Digital Ocean, unlike AWS, does not offer a managed database service like RDS. We will need to roll out our own manually. To provision a server to install the databse onto, we will create another droplet resource, just like we did for the web. Putting everything together, we have:
variable "token" {
default = "xxxx-xxxxx-xxxx-xxxx-xxxx"
}
provider "digitalocean" {
token = "${var.token}"
}
resource "digitalocean_ssh_key" "default" {
name = "SSH Key Credential"
public_key = "${file("/home/vagrant/.ssh/id_rsa.pub")}"
}
resource "digitalocean_droplet" "web" {
count = 2
image = "ubuntu-16-04-x64"
name = "web-${count.index}"
region = "lon1"
size = "1gb"
ssh_keys = ["${digitalocean_ssh_key.default.id}"]
}
resource "digitalocean_droplet" "database" {
image = "ubuntu-16-04-x64"
name = "db-1"
region = "lon1"
size = "1gb"
ssh_keys = ["${digitalocean_ssh_key.default.id}"]
}
resource "digitalocean_loadbalancer" "public_lb" {
name = "public-lb"
region = "lon1"
forwarding_rule {
entry_port = 80
entry_protocol = "http"
target_port = 80
target_protocol = "http"
}
algorithm = "round_robin"
droplet_ids = ["${digitalocean_droplet.web.*.id}"]
}
output "loadbalancer_ip" {
value = "${digitalocean_loadbalancer.public_lb.ip}"
}Code VI
In addition to configuring the resources we have added an output variable, this variable will print out the IP address of our load balancer and we can use this address to setup a DNS A record.
To get thing going and see its effect, we run terraform plan to make sure things are fine and well sorted, then we run terraform apply to build the actual infrastructure. In this part of the series, we have successfully built ourselves a simple infrastructure good enough to host a blog or small web application. In the next part of this series, we will look at how we can level things up even further by provisioning software onto our new cluster.
Disclaimer
While following the examples outlined in this article, please bear in mind that there’s a cost attached to it. When you run terraform plan then terraform apply and create real resources on your provider, they start billing you almost immediately. As a word of caution and this applies only in a non-production environment, always try to clean after yourself. For this purpose, Terraform offers us a really handy command called terraform destroy. The terraform destroy command will delete/destroy every resource that you created in your config. This is a one-way command and cannot be undone, so I strongly advise you do this in your personal or experimental environment.
I'll love to hear from you
Do you want to say hello? Email me - celestineomin@gmail.com
I tweet at @cyberomin
If you enjoyed this post, please consider sharing it. comments powered by Disqus